How Our System Parses and Scrapes Data Automatically
Finding useful data in materials science often means opening dozens of papers, checking tables, and fixing formats by hand. We built a system to make this easier.
Step 1: Collecting Data from Trusted Sources
Our system collects documents from well-known research platforms. These include:
- PubChem
- Google Scholar
- Crossref
- ScienceDirect
- Material Project
It finds and downloads materials-related papers and metadata for further processing.
Step 2: Parsing the Documents
After collecting the documents, the system checks what kind of file it’s dealing with:
- HTML
- XML
- Table
- Scanned image
Each type is handled differently:
- OCR tools read scanned images
- PDF parsers extract content from digital PDFs
- Custom logic handles HTML and table structures
This step turns messy files into readable, structured content.
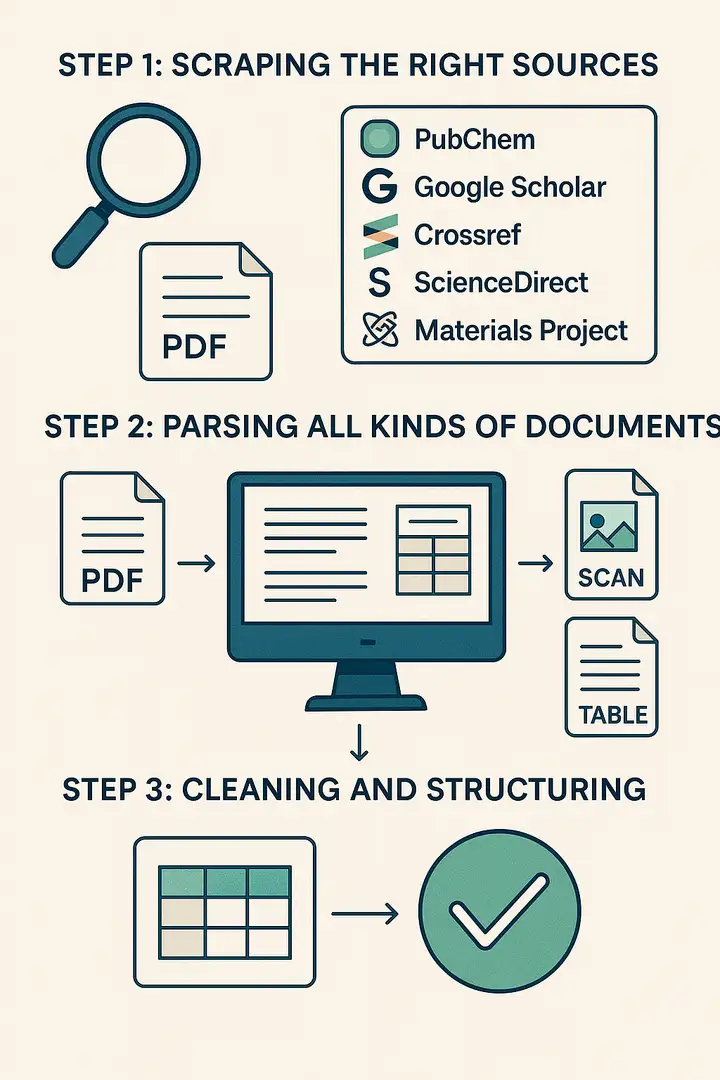
Step 3: Extracting and Cleaning the Data
While parsing, the system:
- Finds important values (dopant, host, formula, etc.)
- Removes duplicate or broken data
- Organizes everything into a consistent format
You get structured, clean material data—without doing the cleanup yourself.
Let the System Do the Hard Work
With this setup, you don’t need to dig through papers or reformat anything. Just search, filter, and use the data directly.
Less time on prep. More time on research.